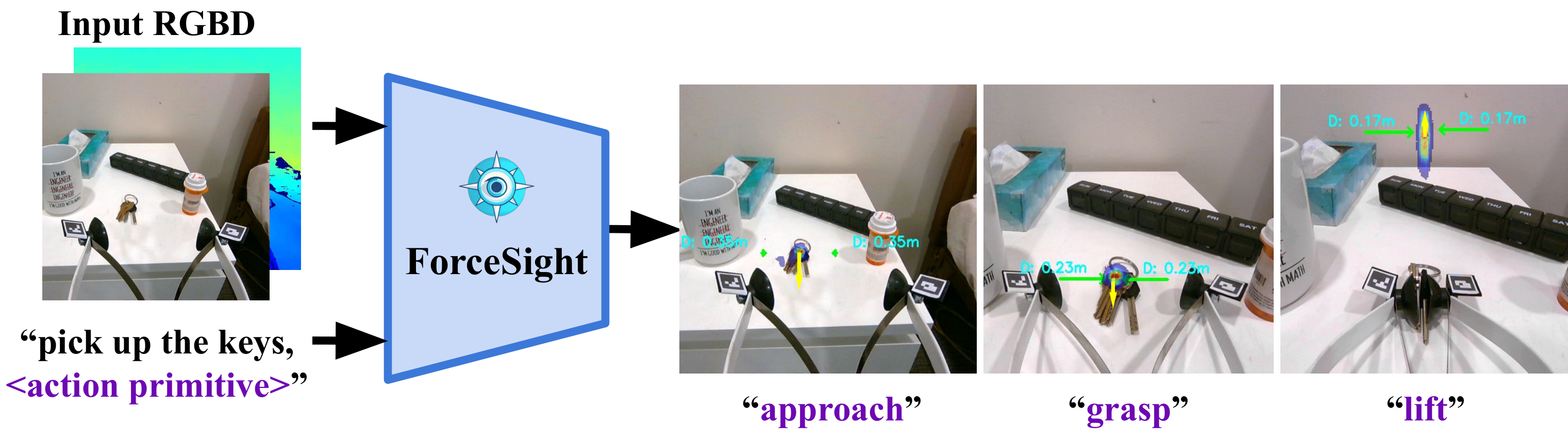
ForceSight is an RGBD-adapted, text-conditioned vision transformer. Given an RGBD image and a text prompt, ForceSight produces visual-force
goals for a mobile manipulator. Action primitives, shown below each image, are appended to the text input by a simple low-level controller.
Summary
We present ForceSight, a transformer-based robotic planner that generates force-based objectives given a text input and an RGBD image, empowering mobile manipulators to plan and execute contact-rich tasks. We demonstrate the utility of ForceSight with 10 mobile manipulation tasks using an eye-in-hand RGBD camera on a mobile manipulator, successfully generalizing to novel environments and unseen object instances. We show that by explicitly predicting force goals, ForceSight predicts forces suitable to the task, operates more effectively, and provides human-interpretable force goals.
"Pick up the paperclip"
"Pick up the apple"
"Open the drawer"
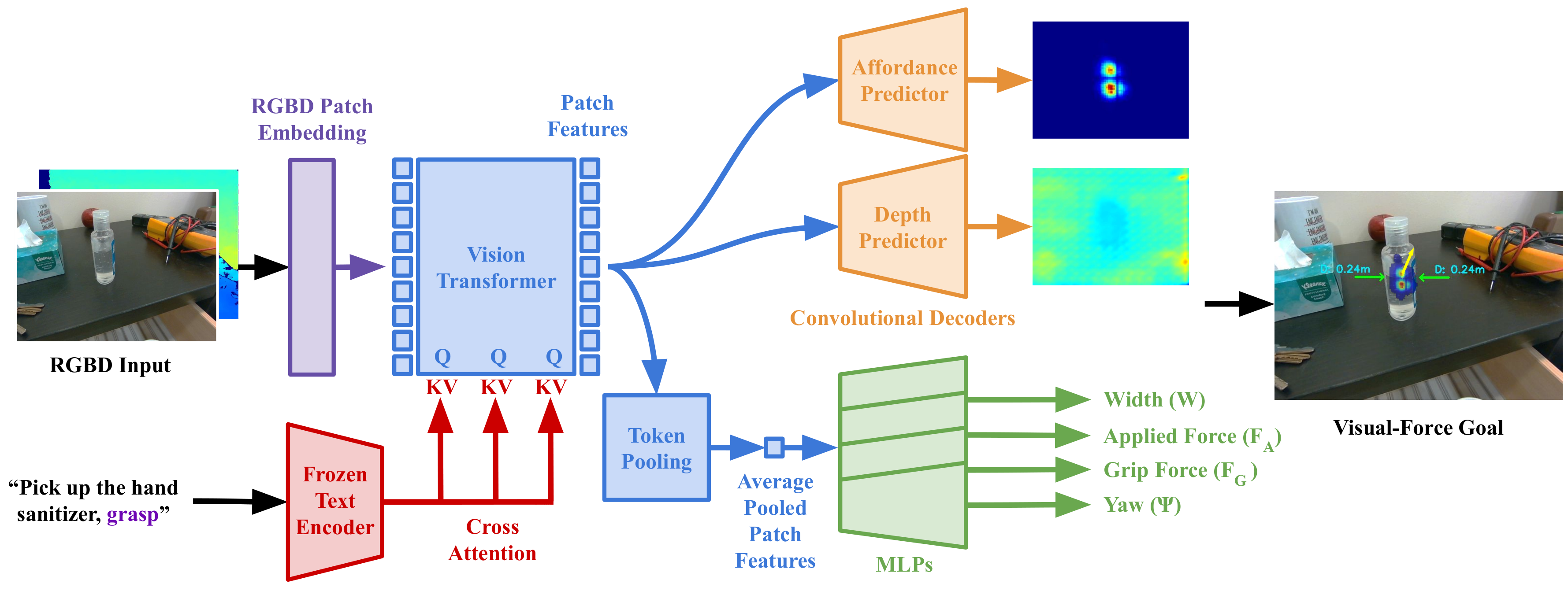
Model Architecture
ForceSight is a text-conditioned RGBD vision transformer. An RGBD image is first divided into patches and passed into an RGBD-adapted patch encoder that transforms image patches into image tokens. These image tokens are fed into a vision transformer. After every transformer block inside the vision transformer, the visual features are conditioned on a text embedding via cross-attention to produce text-conditioned image patch features. These patch features are passed into two convolutional decoders to produce an affordance map and a depth map. The patch features are additionally average pooled and passed into several MLPs in order to predict the gripper width, applied force, grip force, and yaw.
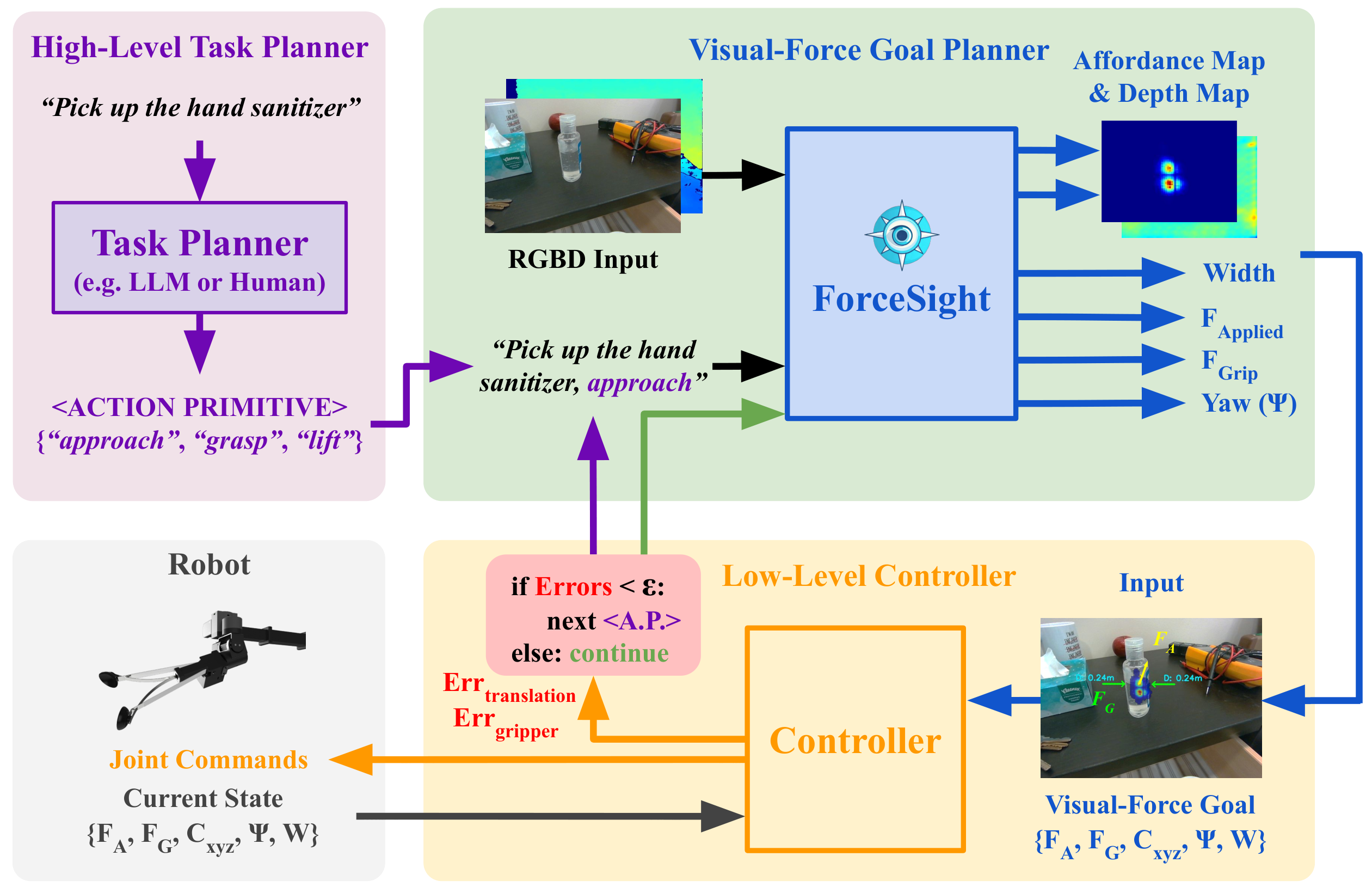
System Architecture
The ForceSight system architecture comprises several components that work together to accomplish a text-conditioned task. It begins with a high-level task planner, which takes a text input and generates a sequence of action primitives representing subgoals. These action primitives, along with the RGBD input, are then passed to the ForceSight transformer model. This model processes the input and produces force-based objectives. These objectives are subsequently fed into the low-level controller, which generates joint motion commands to reach the next goal. To determine when to switch to the next action primitive, the low-level controller compares the error between the current states and visual-force goals with a predefined threshold. If the error is below the threshold, the low-level controller initiates the switch to the next action primitive. This entire process loop operates at a frequency of 8 Hz.
Visual-Force Goals (Left) vs Kinematic Goals w/o Force (Right)
"pick up the keys"
"pick up the paperclip"
"place object in the hand"
Dynamic Object Handover
"place object in the hand"
Continuous Grip Force (Left) vs Binary Gripper Position (Right)
"pick up the cup"
Emergent Properties
Generalization
ForceSight is able to generalize to novel environments and unseen object instances. Left: Objects in the training set. Right: Objects in the test set.
Agent Agnostic
Predictions from ForceSight are agnostic to the agent and camera perspective, as shown in this example for the apple grasping task.
Multi-step prediction
ForceSight is able to make reasonable predictions for action primitives that are more than one keyframe into the future, despite having been trained to predict goals associated with only the next keyframe.
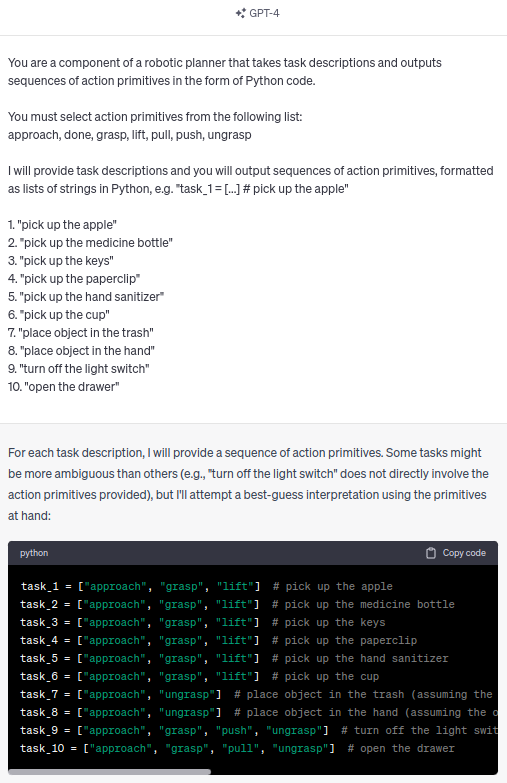
Assigning action primitives with an LLM
We demonstrate how a large language model (GPT-4) could plausibly be used to assign action primitives to task descriptions.
BibTeX
@misc{collins2023forcesight,
title={ForceSight: Text-Guided Mobile Manipulation with Visual-Force Goals},
author={Jeremy A. Collins and Cody Houff and You Liang Tan and Charles C. Kemp},
year={2023},
eprint={2309.12312},
archivePrefix={arXiv},
primaryClass={cs.RO}
}